
Qwen 3发布即开源,性能超DeepSeek R1
阿里正式发布Qwen3,发布即开源,一共8款模型。
包含2种MoE(Mixture of Experts)模型和6种密集模型,参数规模从6亿到2350亿不等。
旗舰模型Qwen3-235B-A22B在编程、数学、通用能力等基准测试中表现出色,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等其他顶尖模型相比,丝毫不差。
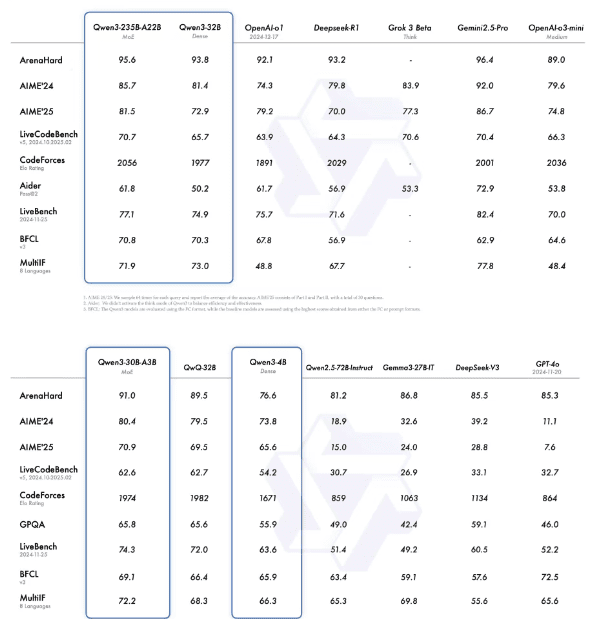
此外,较小的MoE模型Qwen3-30B-A3B在激活参数数量上仅为QwQ-32B的十分之一,但性能却优于后者。
即使是像Qwen3-4B这样小巧的模型,也能与Qwen2.5-72B-Instruct相媲美。
模型特色:思考更深,速度更快
– Qwen3 性能超越DeepSeek R1
– Qwen3 是国内首个混合推理模型,复杂答案深度思考,简单答案直接秒回,自动切换,提升智力+节省算力双向奔赴
– 模型部署要求大幅降低,旗舰模型仅需4张H20就能本地部署,部署成本估算下来是能比R1下降超6成
– Agent 能力大幅提升,原生支持 MCP 协议,提升了代码能力,国内的 Agent 工具都在等它
– 支持119种语言和方言,包括爪哇语、海地语等地方性语言。
– 训练数据 36 万亿 token,相比 Qwen2.5 直接翻倍,不仅从网络抓取内容,还大量提取 PDF 的内容、大量合成代码片段。
– 模型部署要求大幅降低,旗舰模型仅需4张H20就能本地部署,是 R1 的三分之一
模型家族:
2 款 MoE 模型:
旗舰版 Qwen3-235B-A22B,激活参数仅22B,部署成本为 DeepSeek R1 的三分之一。
迷你版 Qwen3-30B-A3B。
6 款 Dense 模型:0.6B、1.7B、4B、8B、14B、32B
0.6B的,可在手机等端侧部署。
Qwen3 已经上线,大家可以在 Qwen Chat 网页版直接体验:https://chat.qwenlm.ai